loading article...
Modern Concurrency in Python - Part 1: "The GIL's Gate"
How Python’s original guard became a bottleneck
•Karol Broda
Most people discover the Global Interpreter Lock the hard way: they launch a “multithreaded” Python job and watch it crawl at single-thread pace. I spent an entire afternoon optimizing a data pipeline before realizing the real bottleneck lived inside CPython itself.
The GIL was introduced to simplify memory management and make CPython’s reference counting safe, but at the cost of true parallelism. In this first installment of Modern Concurrency in Python, we’ll:
- Trace the GIL’s origin and the design trade-offs that brought it into existence
- Sketch its high-level behavior and why “one thread at a time” became the rule
- Share a few cringe-worthy anecdotes so you don’t repeat my debugging misadventures
What is the GIL?
The GIL is a mutex that only allows a single thread to execute Python bytecode at a time. Even if you have multiple threads ready to run, only one can hold the lock and make progress.
The Problem it Solves: Safe Memory Management
CPython, the standard Python interpreter, manages memory using a technique called reference counting. Every object in Python has a counter that keeps track of how many variables or other objects refer to it. When this count drops to zero, it means nothing is using the object anymore, and Python can safely deallocate its memory.
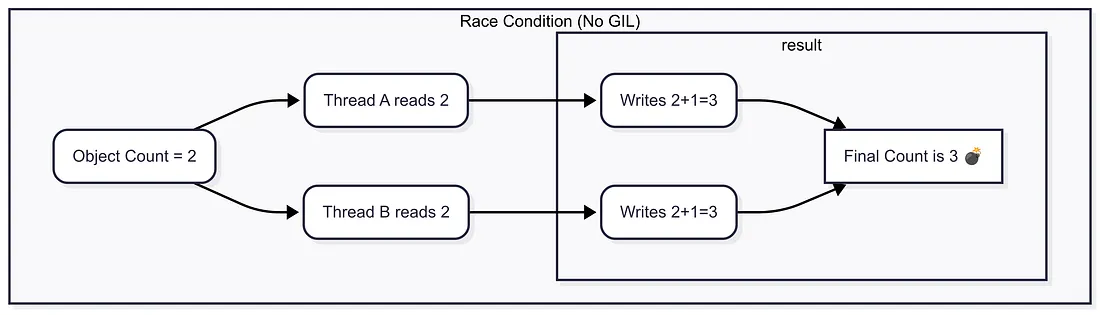
This system is simple and efficient, but it becomes dangerous in a multithreaded environment. Imagine two threads trying to change an object’s reference count simultaneously. This creates a “race condition”:
- Thread A reads the reference count of an object, say it’s
2. - Before Thread A can modify it, the operating system switches execution to Thread B.
- Thread B also reads the reference count, which is still
2. Thread B increments the count to3and writes it back. - The OS switches back to Thread A, which is still holding the old value
2. It increments this to3and writes it back, overwriting the value from Thread B.
The correct reference count should be 4, but it's now 3. This seemingly small error can corrupt memory and lead to crashes or, even worse, memory leaks that are incredibly difficult to debug.

How the GIL Prevents the Race Condition
This is where the GIL comes in. By ensuring only one thread can execute Python bytecode at a time, it acts as a global lock on the interpreter itself. Before a thread can modify any Python object, like changing a reference count, it must first acquire the GIL. This prevents race conditions and keeps memory management safe and predictable, without needing to put a separate lock on every single object, which would significantly slow down the entire system.
In essence, the GIL was a pragmatic design choice: it provided thread safety “for free,” simplifying the CPython implementation and making it easier to integrate C libraries that were not originally designed to be thread-safe.
The GIL in Action: CPU-Bound vs. I/O-Bound
So, if the GIL means “one thread at a time,” does that make Python’s threading module useless? Not at all. The key to understanding when to use threads lies in understanding the type of work you're doing. This is where the crucial distinction between CPU-bound and I/O-bound tasks comes in.
The CPU-Bound Bottleneck
A task is CPU-bound when its speed is limited by the processor. Think of intense mathematical calculations, compressing files, or processing images. These tasks require constant computation.
- How the GIL gets in the way: When a thread is performing a CPU-bound task, it needs to constantly execute Python bytecode, so it tries to hold on to the GIL. Now, imagine you have two threads. Thread A acquires the GIL and starts its work. Thread B is ready to go, but it’s stuck waiting. To prevent one thread from hogging the interpreter, Python forces the running thread to release the GIL periodically. When Thread A is forced to release the lock, Thread B can acquire it and run. But while Thread B is running, Thread A is now paused. They are simply taking turns on a single CPU core. This rapid turn-taking, called context switching, adds its own overhead. The result is zero parallelism, and your program can even run slower than if you had just run the tasks one after the other in a single thread.
- A simple code example:
import time
import threading
from concurrent.futures import ThreadPoolExecutor
def calculate_fibonacci(n):
if n <= 1:
return n
return calculate_fibonacci(n - 1) + calculate_fibonacci(n - 2)
def cpu_intensive_task(task_id, iterations=35):
print(f"task {task_id} starting...")
start_time = time.time()
result = 0
for i in range(3): # calculate fibonacci 35 three times
result += calculate_fibonacci(iterations)
end_time = time.time()
print(f"task {task_id} completed in {end_time - start_time:.2f} seconds, result: {result}")
return result
def run_single_thread():
print("=== single thread execution ===")
start_time = time.time()
results = []
for i in range(2):
result = cpu_intensive_task(i + 1)
results.append(result)
end_time = time.time()
total_time = end_time - start_time
print(f"total time (single thread): {total_time:.2f} seconds\n")
return total_time, results
def run_multi_thread():
print("=== multi-thread execution ===")
start_time = time.time()
results = []
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for i in range(2):
future = executor.submit(cpu_intensive_task, i + 1)
futures.append(future)
for future in futures:
result = future.result()
results.append(result)
end_time = time.time()
total_time = end_time - start_time
print(f"total time (multi-thread): {total_time:.2f} seconds\n")
return total_time, results
if __name__ == "__main__":
print("demonstrating python gil impact on cpu-bound tasks\n")
single_time, single_results = run_single_thread()
multi_time, multi_results = run_multi_thread()
print("=== results comparison ===")
print(f"single thread time: {single_time:.2f} seconds")
print(f"multi-thread time: {multi_time:.2f} seconds")
speedup = single_time / multi_time if multi_time > 0 else 0
print(f"speedup factor: {speedup:.2f}x")
if speedup < 1.5:
print("no significant speedup - gil prevents true parallelism for cpu-bound tasks")
else:
print("unexpected speedup - results may vary based on system")demonstrating python gil impact on cpu-bound tasks
=== single thread execution ===
task 1 starting...
task 1 completed in 2.53 seconds, result: 27682395
task 2 starting...
task 2 completed in 2.58 seconds, result: 27682395
total time (single thread): 5.11 seconds
=== multi-thread execution ===
task 1 starting...
task 2 starting...
task 1 completed in 5.08 seconds, result: 27682395
task 2 completed in 5.07 seconds, result: 27682395
total time (multi-thread): 5.08 seconds
=== results comparison ===
single thread time: 5.11 seconds
multi-thread time: 5.08 seconds
speedup factor: 1.00x
no significant speedup - gil prevents true parallelism for cpu-bound tasksMy “I thought this would be faster” moment: I once had to perform complex text analysis on a few thousand documents. I refactored my code to use a ThreadPoolExecutor with multiple workers, assuming it would fly. When I ran it, I watched my system monitor and saw only one CPU core light up at a time. The total runtime was even a bit longer than my original, simple for loop.
The I/O-Bound Sweet Spot
A task is I/O-bound when its speed is limited by waiting for an external resource. This includes waiting for a network response, querying a database, or reading from a hard drive. The CPU is mostly idle during these waits.
- How the GIL helps (by stepping aside): The story completely changes with I/O-bound tasks. When a Python thread executes an operation that waits for Input/Output, like making a network request or reading a file, it releases the GIL. While Thread A is waiting for a server to respond, it’s not using the CPU, so the interpreter hands the GIL to Thread B. Thread B starts its own I/O operation, releases the GIL in turn, and so on. This allows many threads to be in a state of “waiting” simultaneously. Even though only one thread can execute Python code at any given moment, their waiting periods overlap, leading to a massive reduction in total execution time.
- A simple code example:
import time
import threading
from concurrent.futures import ThreadPoolExecutor
def simulate_api_call(task_id, delay=2.0):
print(f"api call {task_id} starting...")
start_time = time.time()
# simulate network latency
time.sleep(delay)
end_time = time.time()
actual_time = end_time - start_time
print(f"api call {task_id} completed in {actual_time:.2f} seconds")
return f"response_data_{task_id}"
def run_single_thread():
print("=== single thread execution ===")
start_time = time.time()
results = []
for i in range(5):
result = simulate_api_call(i + 1)
results.append(result)
end_time = time.time()
total_time = end_time - start_time
print(f"total time (single thread): {total_time:.2f} seconds\n")
return total_time, results
def run_multi_thread():
print("=== multi-thread execution ===")
start_time = time.time()
results = []
with ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for i in range(5):
future = executor.submit(simulate_api_call, i + 1)
futures.append(future)
for future in futures:
result = future.result()
results.append(result)
end_time = time.time()
total_time = end_time - start_time
print(f"total time (multi-thread): {total_time:.2f} seconds\n")
return total_time, results
if __name__ == "__main__":
print("demonstrating threading benefits for i/o-bound tasks\n")
single_time, single_results = run_single_thread()
multi_time, multi_results = run_multi_thread()
print("=== results comparison ===")
print(f"single thread time: {single_time:.2f} seconds")
print(f"multi-thread time: {multi_time:.2f} seconds")
speedup = single_time / multi_time if multi_time > 0 else 0
print(f"speedup factor: {speedup:.2f}x")
if speedup > 3.0:
print("significant speedup - threading excels at i/o-bound tasks")
else:
print("unexpected results - threading should provide major speedup for i/o")➜ python gil_io_example.py
demonstrating threading benefits for i/o-bound tasks
=== single thread execution ===
api call 1 starting...
api call 1 completed in 2.01 seconds
api call 2 starting...
api call 2 completed in 2.00 seconds
api call 3 starting...
api call 3 completed in 2.01 seconds
api call 4 starting...
api call 4 completed in 2.01 seconds
api call 5 starting...
api call 5 completed in 2.01 seconds
total time (single thread): 10.03 seconds
=== multi-thread execution ===
api call 1 starting...
api call 2 starting...
api call 3 starting...
api call 4 starting...
api call 5 starting...
api call 1 completed in 2.00 seconds
api call 2 completed in 2.00 seconds
api call 3 completed in 2.00 seconds
api call 5 completed in 2.00 seconds
api call 4 completed in 2.00 seconds
total time (multi-thread): 2.01 seconds
=== results comparison ===
single thread time: 10.03 seconds
multi-thread time: 2.01 seconds
speedup factor: 5.00x
significant speedup - threading excels at i/o-bound tasks- The web scraper that changed my mind: A few weeks after my CPU-bound failure, I had to write a script to download a few hundred images from a website. Remembering my last experience, I was hesitant to use threads. But since this was all network waiting, I gave it a shot. The single-threaded version took over a minute. The 10-threaded version? It finished in 7 seconds. It was a night-and-day difference and proved that python threads are the perfect tool for I/O-bound concurrency.
Conclusion: The GIL’s Gate is Not a Wall
The GIL is one of Python’s most misunderstood features. It’s not a mistake, but a design trade-off that has shaped the language for decades. It prevents true parallelism for CPU-heavy tasks in a single process, but it’s not a death sentence for concurrency.
Choose the right tool for the job.
- If your code is spending most of its time waiting (I/O-bound), threading is your best friend.
- If your code is spending most of its time thinking (CPU-bound), you’ll need to look beyond threads and into other tools.
Now that we understand what the GIL does and when it impacts our code, the next part of this series covers how it actually works: thread-switching logic, lock contention costs, and the GIL’s inner mechanics.